MySQL索引优化的性能剖析和总结
发布时间:2022-01-17 13:52 所属栏目:115 来源:互联网
导读:本篇内容主要讲解MySQL索引优化的性能分析和总结,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习MySQL索引优化的性能分析和总结吧! 案例分析 我们先简单了解一下非关系型数据库和关系型数据库的区别。 MongoDB
|
本篇内容主要讲解“MySQL索引优化的性能分析和总结”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“MySQL索引优化的性能分析和总结”吧! 案例分析 我们先简单了解一下非关系型数据库和关系型数据库的区别。 MongoDB 是 NoSQL 中的一种。NoSQL 的全称是 Not only SQL,非关系型数据库。它的特点是性能高,扩张性强,模式灵活,在高并发场景表现得尤为突出。但目前它还只是关系型数据库的补充,它在数据的一致性,数据的安全性,查询的复杂性问题上和关系型数据库还存在一定差距。 MySQL 是关系性数据库中的一种,查询功能强,数据一致性高,数据安全性高,支持二级索引。但性能方面稍逊与 MongoDB,特别是百万级别以上的数据,很容易出现查询慢的现象。这时候需要分析查询慢的原因,一般情况下是程序员 sql 写的烂,或者是没有键索引,或者是索引失效等原因导致的。 公司 ERP 系统数据库主要是 MongoDB(最接近关系型数据的 NoSQL),其次是 Redis,MySQL 只占很少的部分。现在又重新使用 MySQL,归功于阿里巴巴的奇门系统和聚石塔系统。考虑到订单数量已经是百万级以上,对 MySQL 的性能分析也就显得格外重要。 我们先通过两个简单的例子来入门。后面会详细介绍各个参数的作用和意义。 说明:需要用到的 sql 已经放在了 github 上了,喜欢的同学可以点一下 star,哈哈。https://github.com/ITDragonBlog/daydayup/tree/master/MySQL/ 场景一:订单导入,通过交易号避免重复导单 业务逻辑:订单导入时,为了避免重复导单,一般会通过交易号去数据库中查询,判断该订单是否已经存在。 最基础的 sql 语句 mysql> select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ | id | transaction_id | gross | net | stock_id | order_status | descript | finance_descript | create_type | order_level | input_user | input_date | +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ | 10000 | 81X97310V32236260E | 6.6 | 6.13 | 1 | 10 | ok | ok | auto | 1 | itdragon | 2017-08-18 17:01:49 | +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+ 查询的本身没有任何问题,在线下的测试环境也没有任何问题。可是,功能一旦上线,查询慢的问题就迎面而来。几百上千万的订单,用全表扫描?啊?哼! 怎么知道该 sql 是全表扫描呢?通过 explain 命令可以清楚 MySQL 是如何处理 sql 语句的。打印的内容分别表示: id : 查询序列号为 1。 select_type : 查询类型是简单查询,简单的 select 语句没有 union 和子查询。 table : 表是 itdragon_order_list。 partitions : 没有分区。 type : 连接类型,all 表示采用全表扫描的方式。 possible_keys : 可能用到索引为 null。 key : 实际用到索引是 null。 key_len : 索引长度当然也是 null。 ref : 没有哪个列或者参数和 key 一起被使用。 Extra : 使用了 where 查询。 因为数据库中只有三条数据,所以 rows 和 filtered 的信息作用不大。这里需要重点了解的是 type 为 ALL,全表扫描的性能是最差的,假设数据库中有几百万条数据,在没有索引的帮助下会异常卡顿。 初步优化:为 transaction_id 创建索引 mysql> create unique index idx_order_transaID on itdragon_order_list (transaction_id); mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100 | NULL | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+ 这里创建的索引是唯一索引,而非普通索引。 唯一索引打印的 type 值是 const。表示通过索引一次就可以找到。即找到值就结束扫描返回查询结果。 普通索引打印的 type 值是 ref。表示非唯一性索引扫描。找到值还要继续扫描,直到将索引文件扫描完为止。(这里没有贴出代码),显而易见,const 的性能要远高于 ref。并且根据业务逻辑来判断,创建唯一索引是合情合理的。 根据业务逻辑来的,查询结构返回 transaction_id 是可以满足业务逻辑要求的。 场景二:订单管理页面,通过订单级别和订单录入时间排序 业务逻辑:优先处理订单级别高,录入时间长的订单。 既然是排序,首先想到的应该是 order by, 还有一个可怕的 Using filesort 等着你。 (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 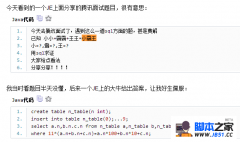 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读