mysql亿级大表重构方案解说
发布时间:2022-03-29 11:27 所属栏目:115 来源:互联网
导读:mysql亿级大表重构方案介绍 生产环境favourite表5.8亿,情况如下: 表名 表结构 rows 数据库版本 favourite CREATE TABLE `favourite` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `target_type` int(11) NOT NULL, `target_id` i
|
mysql亿级大表重构方案介绍 生产环境favourite表5.8亿,情况如下: 表名 表结构 rows 数据库版本 favourite CREATE TABLE `favourite` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `target_type` int(11) NOT NULL, `target_id` int(11) NOT NULL, `created_at` datetime NOT NULL, `status` smallint(6) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), UNIQUE KEY `uniq_user_target` (`user_id`,`target_type`,`target_id`), KEY `idx_targetid` (`target_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 587312519 5.7.12 下面sql因表的量级变的比较慢,已无法通过调整索引或调整sql进行优化: SQL time SELECT count(1) AS count_1 FROM `favourite` WHERE `favourite`.target_id = 636 AND `favourite`.target_type = 1 4.7S SELECT `favourite`.target_id AS `favourite_target_id` FROM `favourite` WHERE `favourite`.user_id = 338072 AND `favourite`.target_type = 0 AND `favourite`.status = 0 ORDER BY `favourite`.id DESC 2.25S DELETE FROM favourite WHERE user_id = 17327373 AND target_id = 917 AND target_type = 1 0.9S 注意: 1)拆分一定要根据业务情况来决定,不能一概而论! 【思路说明】 1、配置好canal ,canal是阿里开源的获取binlog信息的软件。从第一步开始到最后结束,canal一直不停获取binlog信息。 2、在不影响业务的数据库上(此处用的从库)将favourite导出成1024个表对应的文件 3、将导出备份文件导入生产环境 4、将canal获取的数据导入到1024个分表(一直进行直到结束) 5、待分表数据与原大表数据差不多时,在业务不繁忙时,切favourite业务读操作 6、切生产favourite写操作 7、待canal无新的记录产生,整个业务切换完毕 8、结束 下面主要说明问题2实现的方式,一共有两种: items 方案一 方案二 实现手段 mysqldump mycat 拆分耗时 4.5Hour 2Hour 准备时间 3Hour,需要加函数索引 <1Hour,准备mycat环境和mycat对应的数据库 优点 不需要配置mycat环境 时间比方案一节省2Hour,导入目标环境后不需在初始化id 缺点 耗时太久、导入目标环境后还需要初始化id 需要熟悉mycat配置、分库规则 【方式一:mysqldump】 Step1.在从库建立函数索引,耗时3Hour alter table favourite add `vis_user_id` int(11) GENERATED ALWAYS AS ((`user_id` % 1024)) STORED; 注意: 1)要在从库建立函数索引,影响会降低很多,如果能把让生产不访问该从库更好。确保生产环境访问该从库时没有select * from favourite where …..这样的命令 2)如果数据库版本低于5.7无法使用函数索引,那么step2.mysqldump备份一次开启4个并发进程,一次耗时230秒;如果有索引,则为30-60秒 Step2.在从库使用mysqldump的--where参数导出 思路: 1)使用--where=" user%1024=0001"导出成按拆分规则命名的文件,该例子对应文件名为0001.sql,一共会产生1024个这样的文件。 2)然后根据导出的文件名用sed命令替换表名(sed是shell命令) 注意: 1)需要提前创建1024个逻辑库 2)这里是根据方案一提到的函数索引对应的虚拟列vis_user_id来分的,这样可以直接用mycat的枚举分库,如果不想用虚拟列,可以用mycat hash来划分,这个对于数值划分方式等同于user%1024,这个详情参考mycat权威指南 3)需要提前在四个逻辑库里创建好用于mycat访问的数据库用户 4)在创建完1024个逻辑库后,登入mycat,再创建favourite表,这样每个逻辑库都有该表 Step2.使用mysqldump备份文件 为了能快速导入mycat,故根据mycat分成4个实例规则(可以有误差,不一定要完全一样),导出4份不同数据,以便可以同时4份文件灌入mycat 使用mysqldump导出4个文件,以下备份同时进行,耗时20分钟: mysqldump -u$USERNAME -p$PASSWORD -S $SOCKET --default-character-set=utf8mb4 -c --set-gtid-purged=OFF --skip-add-locks --skip-quick --no-create-db --log-error=/data/cyt0324.log --skip-add-drop-table kuaikan favourite --where=" mod(user_id,1024)<256 " > /data/favourite_256.sql mysqldump …………………… --where=" mod(user_id,1024)>=256 and mod(user_id,1024) <512 " > /data/favourite_512.sql mysqldump …………………… --where=" mod(user_id,1024)>=512 and mod(user_id,1024)< 768 " > /data/favourite_768.sql mysqldump …………………… --where=" mod(user_id,1024) >=768" > /data/favourite_1024.sql 注意: 1)请在从库或业务不去访问的数据库上进行备份 2)上面设置的参数请根据实际情况调整,一定要加上-c --skip-add-locks参数,否则导入mycat会异常 Step3.将备份文件导入mycat 将步骤2导出的四个备份文件同时灌入mycat,整个耗费时间不足90分钟。 (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 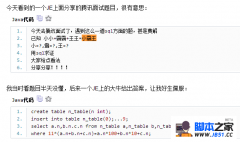 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读