今日头条这类 App,如何知道你喜欢看什么?
不了解今日头条是怎么运作的。不过因为在 Facebook 工作时负责新鲜事(Newsfeed)的个性化推荐与排序,我可以说说 Facebook 是怎么衡量自己推荐和排序的质量的。 在具体执行层面,主要有 3 个方式,分别是从机器学习模型、产品数据,和用户调查上来考核推荐引擎的效果。 1. 机器学习模型推荐引擎的一大核心就是机器学习(不过现在都说人工智能了,但本质上还是 supervised learning)。如果是想考察机器学习模型的质量,学术上早就有一套成熟的实践方法。 无论是模型的选择(比如从 decision tree 替换成 neural network),还是迭代改进(比如模型训练时多用一倍的数据),都可以使用基于 supervised learning 的衡量办法。最常见的就是 AUC。 另一方面,对于某一类特定问题也有更细致的指标。比如说,可以通过模型特征的重要性(feature importance)知道新加的特征是不是有用。
2. 产品数据再牛逼的机器学习模型都要经历产品数据的实际检验。这方面大家就都比较熟悉了,KPI 嘛。不过在 Facebook 特别是 Newsfeed 这种牵一发动全身的地方,我们会追踪一系列数据来描述产品,而不是依赖某一个单一标准。 这些数据包括但不限于:
而且,在日常的快速迭代和 A/B 测试中,只有这些笼统的数据是不够的,我们还需要些更细致的数据来真正理解我们的一些改动。比如说:
另外,为了防止短暂的眼球效应,对每一个重要的产品决策,我们都会维护一个长期的 backtest,用来评估这个决策的长久影响。比如说:
这样,对每一个可能会有争议的决策,但未来的每个时间点,我们都能清楚地知道,我们是面临着怎样的取舍。有了这层保障,在决策的当下,我们也就敢于冒险些,走得更快些。
3. 用户调查大多数产品数据有其局限性,因为它们是显性而被动的。比如说,你给用户推送了一个博眼球的低俗内容,用户在当下可能是会去点开看的,所以数据上是好的。 但用户可能心里对这个内容的评价是低的,连带着对作为内容平台的产品也会看轻,长此以往对产品的伤害是巨大的。 KPI 无法完全描述产品质量,在硅谷互联网圈是有共识的,但如何解决,每个公司答案都不同。 Twitter 系的 CEO 们,无论是 Jack Dorsey 还是 Evan Williams,都倾向于轻视 KPI 而依赖自己主观想法来决策。 Google 和 Facebook,则采取了另一条路,他们决定把用户评价纳入到 KPI 中。 Google 在这方面的工作开始得比较早,因此公开的资料也比较多。概括地说,他们雇佣大量的普通人,以用户的角度来对 Google 搜索排序的质量和广告推荐的质量做主观打分。 当打分的量大到一定程度,这些数据就足以成为一个稳定有效的,且可持续追踪并改进的 KPI 了。Facebook 虽然产品领域有所不同,但在个性化推荐上也采取了类似的方法。 回答的最后,还是想重申两个方法论:
(编辑:ASP站长网) |


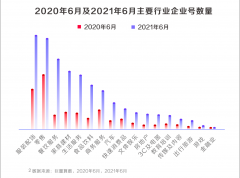 《2021抖音私域经营白
《2021抖音私域经营白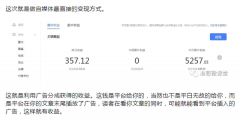 副业刚需 一文带你全
副业刚需 一文带你全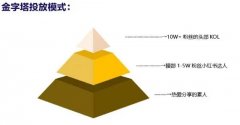 小红书如何自建鱼塘获
小红书如何自建鱼塘获 物联网产品设计中Wi-F
物联网产品设计中Wi-F